量子计算机有可能彻底改变药物发现、材料设计和基础物理学--前提是,我们能够让它们可靠地工作。
如今,人工智能(AI)也有望彻底改变量子计算机。
今日凌晨,谷歌发布了一种基于 Transformers、能够以最先进的精度识别量子计算错误的解码器——AlphaQubit,加快了构建可靠量子计算机的进度。
谷歌 CEO Sundar Pichai 在 X 上写道,“AlphaQubit 利用 Transformers 对量子计算机进行解码,在量子纠错准确性方面达到了新的技术水平。人工智能与量子计算的交汇令人兴奋。”

相关研究论文以“Learning high-accuracy error decoding for quantum processors”为题,已发表在权威科学期刊 Nature 上。

准确识别错误,是使量子计算机能够大规模执行长时间计算的关键一步,为科学突破和许多新领域的发现打开了大门。
纠正量子计算错误
量子计算机利用物质在最小尺度上的独特特性,如叠加和纠缠,以比经典计算机少得多的步骤解决某些类型的复杂问题。这项技术依赖于量子比特(或量子位 ),量子比特可以利用量子干扰筛选大量的可能性,从而找到答案。
量子比特的自然量子态会受到各种因素的破坏:硬件中的微小缺陷、热量、振动、电磁干扰甚至宇宙射线(宇宙射线无处不在)。
量子纠错通过使用冗余提供了一个解决方案:将多个量子比特组合成一个逻辑量子比特,并定期对其进行一致性检查。解码器通过使用这些一致性检查来识别逻辑量子比特中的错误,从而保存量子信息,并对其进行纠正。
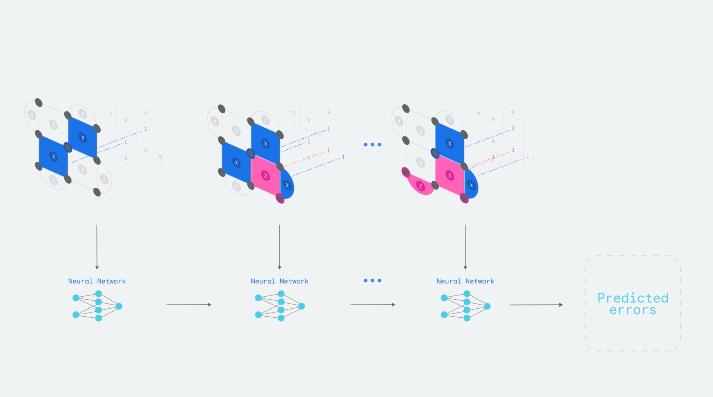
图|边长为 3(码距)的量子比特网格中的 9 个物理量子比特(灰色小圆圈)是如何构成逻辑量子比特的。在每个时间步中,还有 8 个量子比特执行一致性检查(正方形和半圆形区域,失败时为蓝色和品红色,否则为灰色),为 AlphaQubit 提供信息。实验结束时,AlphaQubit 会确定发生了哪些错误。
创建神经网络解码器
AlphaQubit 是基于神经网络的解码器,它借鉴了谷歌开发的深度学习架构 Transformers,该架构是当今许多大语言模型(LLM)的基础。利用一致性检查作为输入,它的任务是正确预测逻辑量子比特在实验结束时的测量结果是否与准备时的结果相反。
研究团队首先对模型进行了训练,从而解码来自 Sycamore 量子处理器(量子计算机的中央计算单元)内一组 49 量子比特的数据。为了教会 AlphaQubit 解决一般的解码问题,他们使用量子模拟器生成了数以亿计的示例,这些示例跨越了各种设置和误差水平。然后,他们通过给 AlphaQubit 提供来自特定 Sycamore 处理器的数千个实验样本,针对特定的解码任务对其进行微调。
在新的 Sycamore 数据上进行测试时,AlphaQubit 与之前的前沿解码器相比,在准确性方面树立了新的标准。在最大规模的 Sycamore 实验中,AlphaQubit 的错误率比张量网络方法低 6%,而张量网络方法虽然精度高,但速度却非常慢。AlphaQubit 的错误率也比相关匹配法低 30%,后者是一种精确的解码器,速度快到足以扩展。
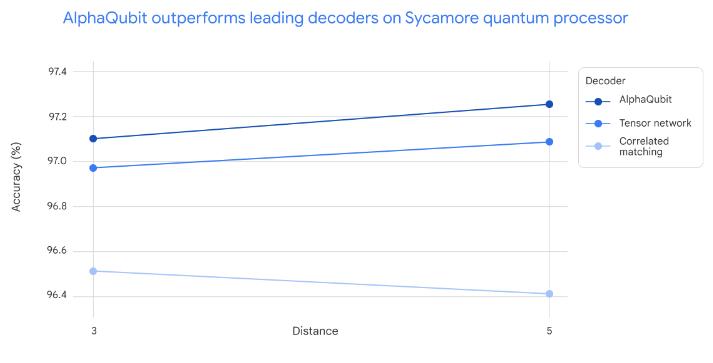
图|小型和大型 Sycamore 实验的解码精度(距离 3 = 17 个物理量子比特,距离 5 = 49 个物理量位)。AlphaQubit 比张量网络(TN,一种无法在大型实验中扩展的方法)和相关匹配(一种速度可扩展的精确解码器)更精确。
泛化到训练数据以外
为了了解 AlphaQubit 如何适应误差水平较低的大型设备,研究团队使用多达 241 量子比特的模拟量子系统数据对其进行了训练,因为这超出了 Sycamore 平台的可用范围。
同样,AlphaQubit 的性能也优于领先的算法解码器,这表明它将来也能用于中型量子设备。
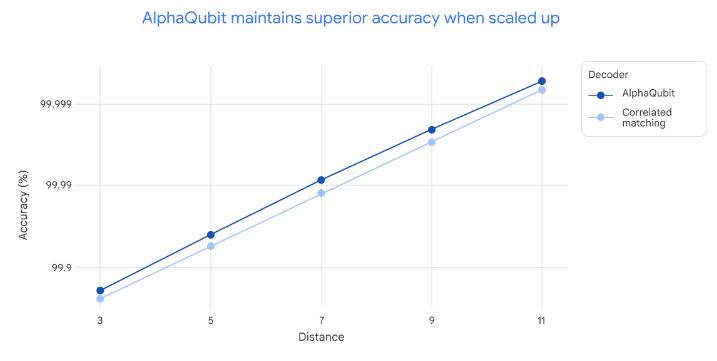
图|从距离 3(17 量子比特)到距离 11(241 量子比特)不同规模/模拟实验的解码精度。张量网络解码器没有出现在此图中,因为它的速度太慢,无法在大距离下运行。其他两个解码器的精确度随着距离的增加(即使用更多物理比特)而提高。在每个距离上,AlphaQubit 都比相关匹配更精确。
AlphaQubit 还展示了一些先进功能,比如接受和报告输入和输出的置信度。这些信息丰富的接口有助于进一步提高量子处理器的性能。
当研究团队在包含多达 25 轮纠错的样本上对 AlphaQubit 进行训练时,它在多达 100000 轮的模拟实验中保持了良好的性能,这表明它有能力泛化到训练数据以外的场景。
实时纠错仍须加速
谷歌表示,AlphaQubit 是利用机器学习进行量子纠错的一个重要里程碑。但他们仍然面临着速度和可扩展性方面的重大挑战。
例如,在快速超导量子处理器中,每个一致性检查每秒要测量一百万次。虽然 AlphaQubit 在准确识别错误方面非常出色,但要在超导处理器中实时纠错,它的速度仍然太慢。随着量子计算的发展,商业应用可能需要数百万量子比特,这亟需更高效的数据方法来训练基于人工智能的解码器。
整理:学术君
如需转载或投稿,请直接在公众号内留言
