今日值得关注的大模型前沿论文
GenEx:一张图,任意生成高质量、可探索世界!
Meta 推出多模态大模型 Apollo:轻松理解一小时长视频
微软新作:大型行动模型 LAM 综述
中科院、北航团队提出「视觉音乐桥接」,增强多模态音乐生成
SnapGen:极小、快速的高分辨率“文生图”模型
Lyra:高效、全认知多模态大语言模型
EasyRef:即插即用的扩散模型适配方法
微软提出「多模态潜在语言建模」,无缝整合离散、连续数据
想要第一时间获取每日最新大模型热门论文?
点击阅读原文,查看「2024必读大模型论文」合集,以及申请加入「大模型技术分享群」。
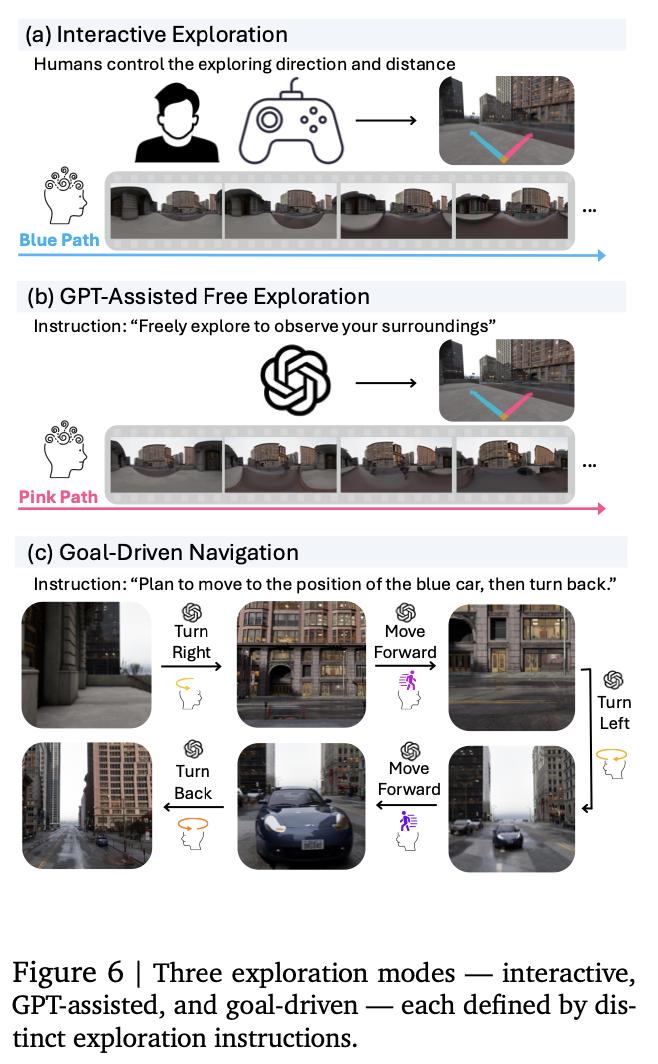
1.GenEx:一张图,任意生成高质量、可探索世界!
理解、导航和探索三维物理现实世界,一直是人工智能发展的关键挑战。在这项工作中,来自约翰霍普金斯大学的研究团队通过提出 GenEx 向这一目标迈出了一步。
GenEx 是一个能够规划复杂的具身世界探索的系统,由其生成的想象力引导,形成对周围环境的先验(预期),只需一张 RGB 图像就能生成整个三维一致的想象环境,并通过全景视频流使之栩栩如生。利用从虚幻引擎中提取的可扩展三维世界数据,GenEx 在物理世界中得到了完善,可以轻松捕捉到连续的 360 度环境,为智能体(agent)探索和互动提供了广阔的景观。
GenEx 实现了高质量的世界生成,在长轨迹上具有鲁棒的循环一致性,并展示了强大的三维能力,如一致性和主动三维映射。在对世界的生成性想象力的支持下,GPT 辅助智能体能够执行复杂的具身任务,包括目标无关的探索和目标驱动的导航。这些智能体利用对物理世界未见部分的预测期望来完善自己的信念,模拟基于潜在决策的不同结果,并做出更明智的选择。
研究团队表示,GenEx 可以在想象空间中推进具身人工智能,并为将这些能力扩展到现实世界的探索带来了潜力。
论文链接:
https://arxiv.org/abs/2412.09624
项目地址:
https://www.genex.world/
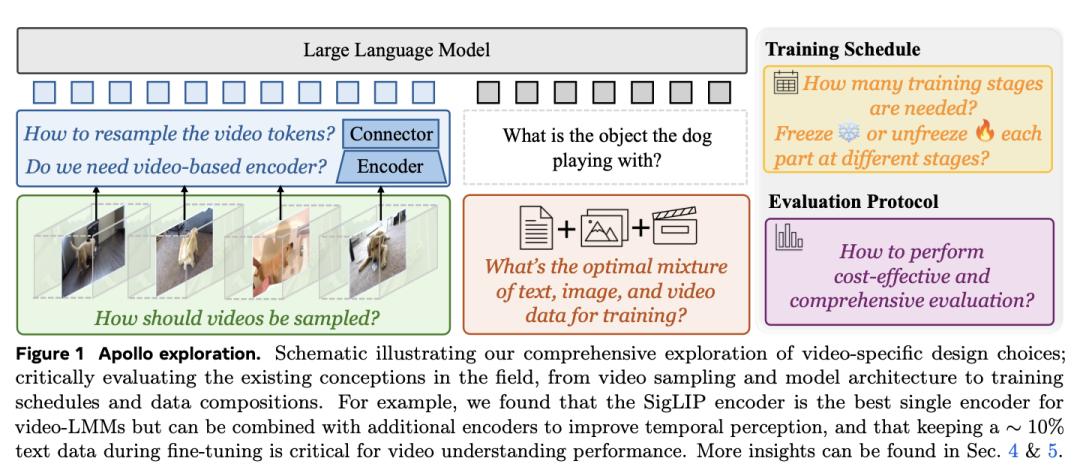
2.Meta 推出多模态大模型 Apollo:轻松理解一小时长视频
尽管视频感知能力已迅速融入大型多模态模型(LMM),但人们对驱动其视频理解的基本机制仍然知之甚少。因此,该领域的许多设计决策都没有经过适当的论证或分析。训练和评估此类模型的计算成本很高,加上公开研究有限,阻碍了视频 LMM 的发展。
为了解决这个问题,Meta 团队开展了一项综合研究,帮助揭示 LMMs 中有效推动视频理解的因素。他们首先批判性地检查了造成视频 LMM 研究相关计算要求高的主要原因,并发现了扩展一致性(Scaling Consistency),即在较小模型和数据集(达到临界规模)上做出的设计和训练决策可有效转移到较大模型上。利用这些见解,他们探索了视频 LMM 的许多特定方面,包括视频采样、架构、数据组成、训练计划等。例如,他们证明了训练过程中的帧采样比统一帧采样更为可取,以及哪种视觉编码器最适合视频表示。
在这些发现的指导下,他们推出了 Apollo,这是一个 SOTA LMM 系列,在不同规模的模型中都能实现有竞争力的性能。这一模型可以高效地感知长达一小时的视频,其中 Apollo-3B 在 LongVideoBench 上以 55.1 的得分超越了大多数现有的 7B 模型。与 7B LMM 相比,Apollo-7B 的 MLVU 和 Video-MME 分别为 70.9 和 63.3,处于先进水平。
论文链接:
https://arxiv.org/abs/2412.10360
项目地址:
https://apollo-lmms.github.io/
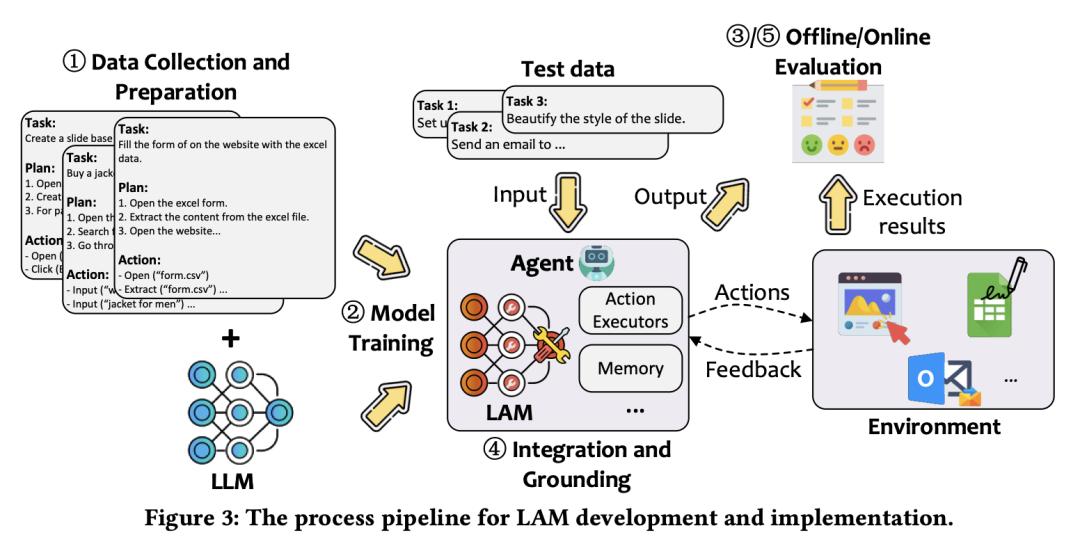
3.微软新作:大型行动模型 LAM 综述
人们对人工智能(AI)系统的需求已经超越了基于语言的辅助,转向能够执行真实世界行动的智能体(agent)。这种演变要求从擅长生成文本响应的传统大型语言模型(LLM)过渡到大型行动模型(LAM),后者专为在动态环境中生成和执行行动而设计。在智能体系统的支持下,LAM 有可能将人工智能从被动的语言理解转变为主动的任务完成,成为通用人工智能发展过程中的一个重要里程碑。
在这项工作中,来自微软的研究团队及其合作者提出了开发 LAMs 的综合框架,为 LAMs 的创建(从开始到部署)提供了一种系统方法。他们首先概述了 LAM,强调了它们的独特性,并划分了它们与 LLM 的区别。他们以一个基于 Windows 操作系统的智能体为案例,详细介绍了 LAM 开发的关键阶段,包括数据收集、模型训练、环境集成、落地和评估。最后,他们指出了 LAM 目前的局限性,并讨论了未来研究和工业部署的方向,强调了在现实应用中充分发挥 LAM 潜力所面临的挑战和机遇。
论文链接:
https://arxiv.org/abs/2412.10047
GitHub 地址:
https://github.com/microsoft/UFO/tree/main/dataflow
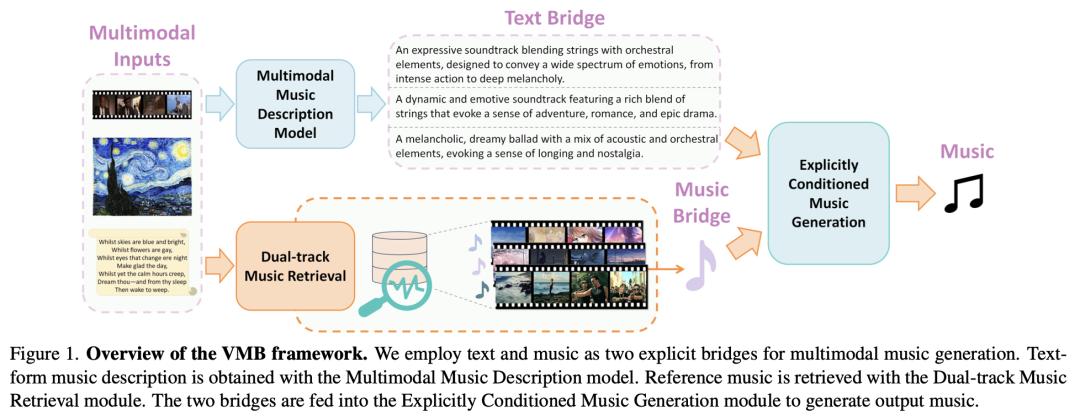
4.中科院、北航团队提出「视觉音乐桥接」,增强多模态音乐生成
现有多模态音乐生成方法使用通用嵌入空间进行多模态融合。尽管这些方法在其他模态中非常有效,但在多模态音乐生成中的应用却面临着数据稀缺、跨模态对齐能力弱和可控性有限等挑战。
来自中国科学院、北京航空航天大学的研究团队及其合作者,提出了视觉音乐桥接(Visuals Music Bridge,VMB),通过使用文本和音乐的显式桥接(explicit bridge)来实现多模态对齐,从而解决了上述问题。具体来说,多模态音乐描述模型将视觉输入转换为详细的文字描述,以提供文字桥接;双轨音乐检索模块结合了广泛和有针对性的检索策略,以提供音乐桥接并实现用户控制。最后,他们设计了一个显式条件音乐生成框架,根据这两个桥接生成音乐。
他们进行了视频到音乐、图像到音乐、文本到音乐和可控音乐生成任务的实验,以及可控性实验。结果表明,与以前的方法相比,VMB 能显著提高音乐质量、模态和定制排列。VMB 为可解释、有表现力的多模态音乐生成设定了新标准,可应用于各种多媒体领域。
论文链接:
https://arxiv.org/abs/2412.09428
GitHub 地址:
https://github.com/wbs2788/VMB
5.SnapGen:极小、快速的高分辨率“文生图”模型
现有的文本到图像(T2I)扩散模型面临几个限制,包括模型规模大、运行速度慢以及在移动设备上生成的图像质量低。
来自 Snap 的研究团队及其合作者旨在通过开发一种极小且快速的 T2I 模型,在移动平台上生成高分辨率和高质量的图像,从而应对所有这些挑战。为实现这一目标,他们提出了几种技术。首先,他们系统地检查了网络架构的设计选择,以减少模型参数和延迟,同时确保高质量的生成。其次,为了进一步提高生成质量,他们从一个更大的模型中采用了跨架构知识提炼,使用多层次方法指导他们的模型从头开始训练。第三,他们通过将对抗指导与知识提炼相结合,实现了几步生成。
他们的模型 SnapGen 在移动设备上生成 1024x1024 px 图像的时间仅为 1.4 秒。在 ImageNet-1K 上,模型只需 372M 参数就能生成 256x256 px 的图像,FID 达到 2.06。在 T2I 基准(即 GenEval 和 DPG-Bench)上,他们的模型仅有 379M 个参数,以明显更小的规模(例如,比 SDXL 小 7 倍,比 IF-XL 小 14 倍)超越了拥有数十亿个参数的大模型。
论文链接:
https://arxiv.org/abs/2412.09619
项目地址:
https://snap-research.github.io/snapgen/
6.Lyra:高效、全认知多模态大语言模型
随着多模态大语言模型(MLLMs)的发展,超越单领域的能力对于满足更多功能和更高效的人工智能需求至关重要。然而,以前的综合模型对语音的探索不够,忽视了语音与多模态的融合。
来自香港中文大学、思谋科技和香港科技大学的研究团队推出的 Lyra 是一种高效的 MLLM,可增强多模态能力,包括高级长语音理解、声音理解、跨模态效率和无缝语音交互。为了实现高效和以语音为中心的能力,Lyra 采用了三种策略:(1)利用现有的开源大模型和建议的多模态 LoRA 来降低训练成本和数据要求;(2)使用潜在多模态正则化器和提取器来加强语音和其他模态之间的关系,从而提高模型性能;以及(3)构建一个高质量、广泛的数据集,其中包括 1.5M 多模态(语言、视觉、音频)数据样本和 12K 长语音样本,使 Lyra 能够处理复杂的长语音输入,实现更鲁棒的全方位认知。
与其他全方位方法相比,Lyra 在各种视觉-语言、视觉-语音和语音-语言基准测试中取得了 SOTA 的性能,同时还使用了更少的计算资源和训练数据。
论文链接:
https://arxiv.org/abs/2412.09501
项目地址:
https://lyra-omni.github.io/
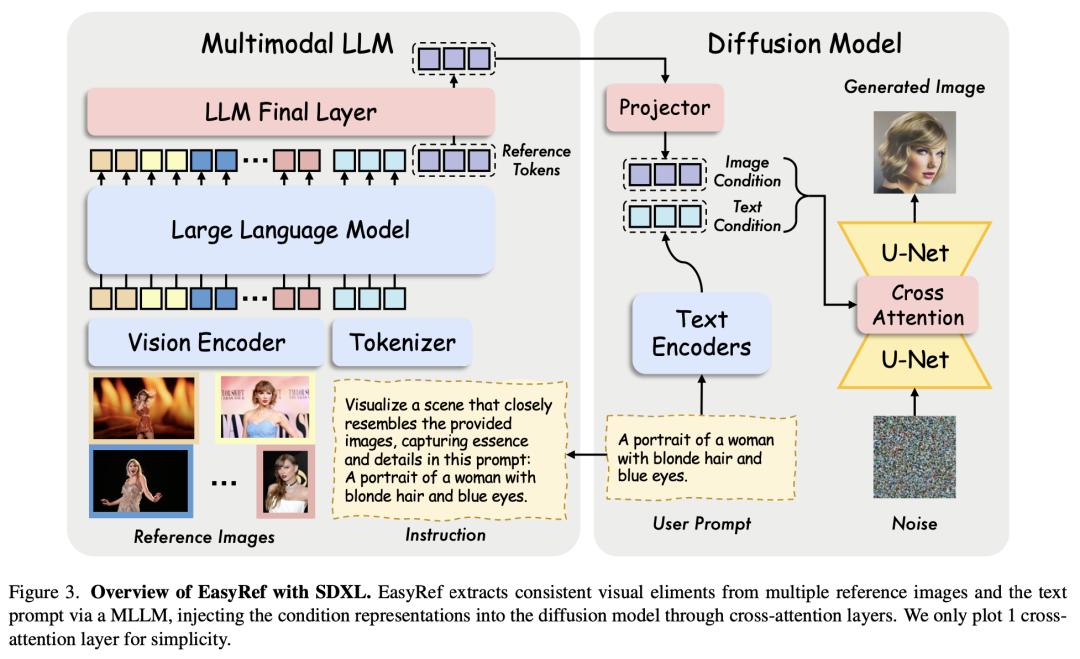
7.EasyRef:即插即用的扩散模型适配方法
传统的扩散模型免微调方法大多以平均图像嵌入作为注入条件,对多个参考图像进行编码,但这种独立于图像的操作无法在图像之间进行交互,从而捕捉多个参考图像中一致的视觉元素。虽然基于微调的低秩适应(LoRA)可以通过训练过程有效地提取多个图像中的一致元素,但它需要针对每个不同的图像组进行特定的微调。
来自香港中文大学多媒体实验室的研究团队及其合作者,提出了一种新颖的即插即用适配方法 EasyRef,它能使扩散模型以多个参考图像和文本提示为条件。为了有效利用多幅图像中一致的视觉元素,他们利用了多模态大语言模型(MLLM)的多图像理解和指令跟踪能力,促使其根据指令捕捉一致的视觉元素。此外,通过适配器将多模态大语言模型的表征注入扩散过程,可以很容易地推广到未见领域,挖掘未见数据中的一致视觉元素。
为了降低计算成本并加强细粒度细节保护,他们提出了一种高效的参考聚合策略和渐进式训练方案。最后,他们提出了一种新的多参考图像生成基准 MRBench。实验结果表明,EasyRef 超越了免微调方法(如 IP-Adapter)和基于微调的方法(如 LoRA),在不同领域实现了卓越的美学质量和鲁棒 的零样本泛化。
论文链接:
https://arxiv.org/abs/2412.09618
项目地址:
https://easyref-gen.github.io/
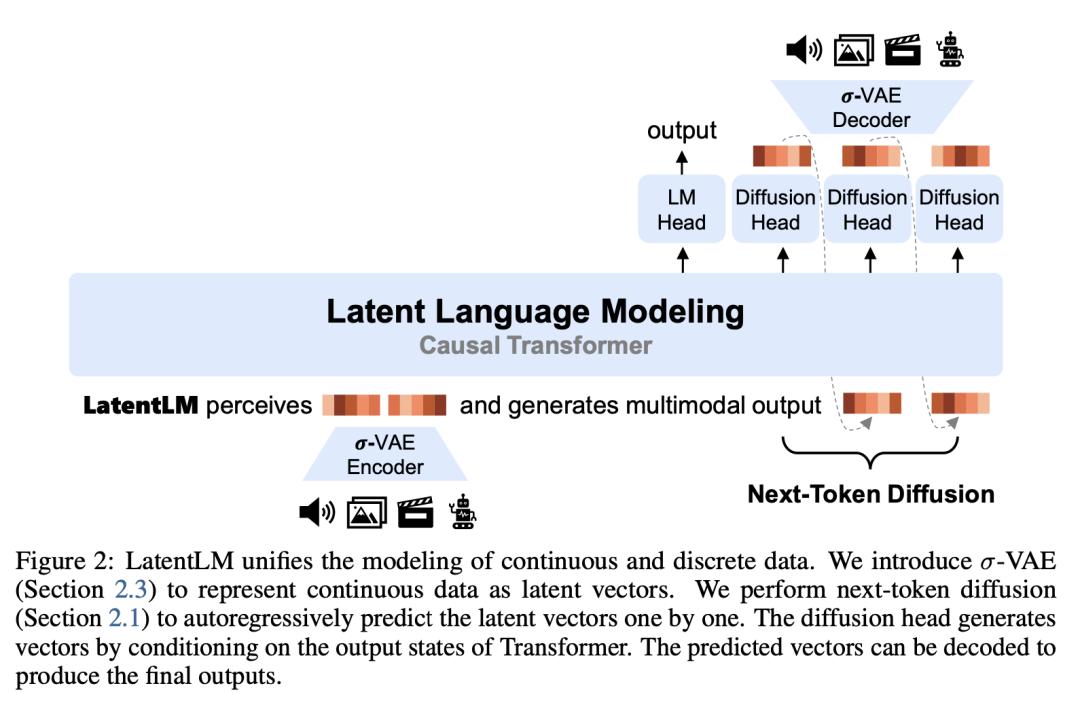
8.微软提出「多模态潜在语言建模」,无缝整合离散、连续数据
多模态生成式模型需要一种统一的方法来处理离散数据(如文本和代码)和连续数据(如图像、音频和视频)。
在这项工作中,来自微软研究院和清华大学的研究团队提出了潜在语言建模(LatentLM),利用因果 Transformer 将连续数据和离散数据无缝整合在一起。具体来说,他们采用变分自编码器(VAE)将连续数据表示为潜在向量,并引入下一个 token 扩散来自回归生成这些向量。此外,他们还开发了 σ-VAE 来应对方差崩溃的挑战,这对自回归建模至关重要。广泛的实验证明了 LatentLM 在各种模态下的有效性。
在图像生成方面,LatentLM 的性能和可扩展性都超过了扩散 Transformer。当集成到多模态大语言模型中时,LatentLM 提供了一个统一多模态生成和理解的通用接口。实验结果表明,在扩大训练 token 的情况下,LatentLM 与 Transfusion 和矢量量化模型相比取得了良好的性能。在文本到语音合成中,LatentLM 在说话人相似性和鲁棒性方面优于 SOTA 的 VALL-E 2 模型,同时所需的解码步骤减少了 10 倍。这些结果证明 LatentLM 是推进多模态大模型的一种高效、可扩展的方法。
论文链接:
https://arxiv.org/abs/2412.08635